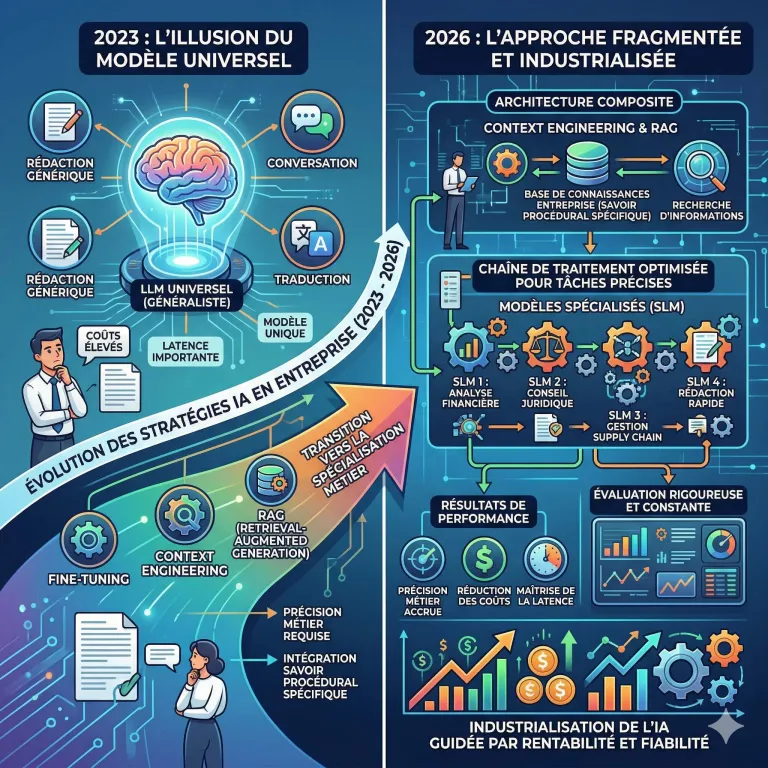
Aujourd'hui, le pivot est total. Nous sommes sortis de l’ère du « prompt-and-pray » (tester et espérer) pour entrer dans celle de la fiabilité industrielle. La question stratégique n'est plus de savoir quel est le modèle le plus puissant du moment, mais comment orchestrer une architecture composite pour passer d'un prototype séduisant à une solution métier rentable, prédictible et souveraine.
Point d'impact 1 : La fin du fantasme de l'omniscience (Le Context Engineering)
Pendant deux ans, le RAG (Retrieval-Augmented Generation) a été la béquille de l’IA, perçu comme le remède miracle à l'amnésie des modèles. Mais en 2026, les leaders de la tech ont compris que « donner des documents » ne suffit pas. Le RAG permet de retrouver une information, mais il échoue souvent à capturer le savoir procédural : ce fameux « comment faire », l'ordre précis des étapes, les contrôles de conformité et la gestion des exceptions qui constituent la véritable intelligence opérationnelle d'une entreprise.
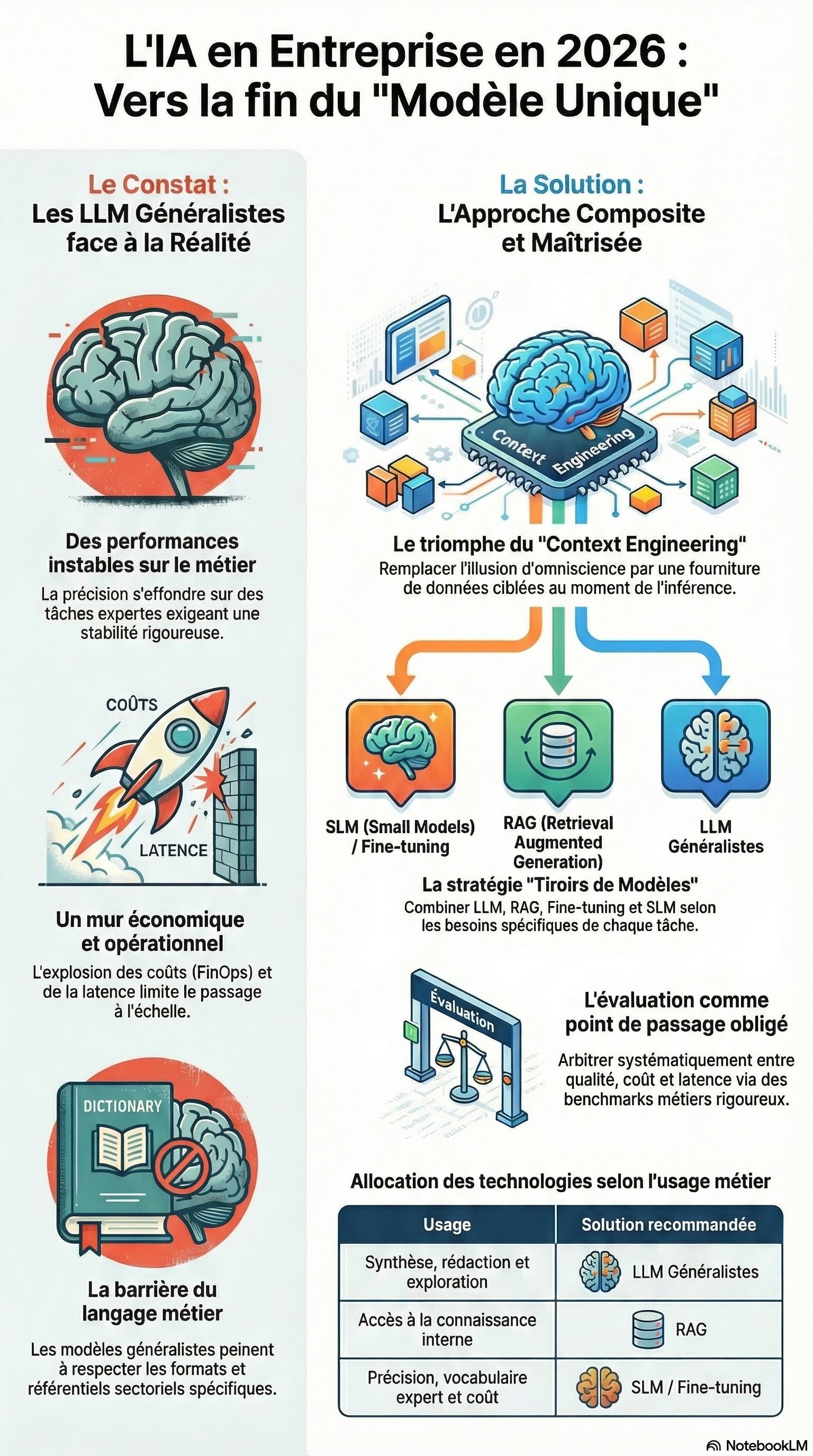
C’est ici qu’émerge le Context Engineering. On abandonne l'illusion d'un modèle omniscient pour une ingénierie contrôlée où l'on fournit explicitement au modèle, au moment de l'inférence, les informations logiques nécessaires à son raisonnement.
Dans cette discipline, la logique d'exécution prime sur le vocabulaire. Le modèle ne sert plus de base de données, mais de moteur de raisonnement sur des données ciblées et des règles métier strictes.
Point d'impact 2 : Pourquoi le « petit » devient le nouveau « grand » (L'essor des SLM)
Le passage à l'échelle a révélé une faille majeure des LLM généralistes : leur instabilité sur les tâches de haute précision. En production, les entreprises constatent souvent que là où des modèles analytiques « classiques » maintenaient des standards élevés, les solutions de GenAI affichent des résultats inférieurs dès qu'on les évalue avec sérieux.
L’essor des SLM (Small Language Models) répond à cette exigence de performance et de sobriété opérationnelle. Pour un décideur, les arguments sont désormais dictés par le FinOps :
Performance métier : Les SLM atteignent une précision chirurgicale sur des domaines experts là où les géants s'éparpillent.
Latence industrielle : Ce qui fonctionne en démonstration devient inopérant si le temps de réponse n'est pas quasi-instantané lors de volumes importants.
Équilibre financier : Orchestrer des appels récurrents vers des modèles géants crée une dette architecturale et des coûts d'inférence insoutenables.
« Les modèles LLM locaux, plus petits, ou hybrides, offrent des performances largement suffisantes pour beaucoup de tâches : ils constituent une alternative très intéressante » — Damien Wattez, Directeur IA et Innovation numérique chez SNCF Voyageurs - TGV Europe.
Point d'impact 3 : La stratégie des « tiroirs de modèles »
En 2026, la maturité technologique se traduit par une stratégie de composition. Plutôt que de tout faire reposer sur un seul bloc monolithique, on utilise des modèles spécialisés comme les maillons d’une chaîne de traitement. Par exemple, une architecture robuste pour le service client utilisera désormais un modèle dédié à la transcription, un autre à l'extraction structurée des données, et un dernier pour le résumé ou la réponse.
Cette approche « tiroirs de modèles » se structure autour de rôles clairs :
LLM généralistes : Cantonnés aux usages larges comme l'assistance, la synthèse créative ou l'exploration.
RAG (Retrieval-Augmented Generation) : Utilisé pour ancrer l’IA dans le patrimoine documentaire de l’entreprise lorsqu'il faut citer des sources internes.
Fine-tuning : Déployé pour garantir un style spécifique, respecter une politique de réponse stricte ou maîtriser un format de données complexe.
SLM / Modèles spécialisés : Privilégiés dès que la précision, le coût et le vocabulaire technique deviennent les facteurs critiques de succès.
Point d'impact 4 : L'évaluation, juge de paix de l'IA industrielle
La spécialisation n'a de sens que si elle est mesurée. Le plus grand enseignement de ces dernières années est le décalage flagrant entre la « perception intuitive » (l'effet "wow" d'une démo) et la performance réelle en production.
Le marché bascule vers une discipline de fer où l'arbitrage est rationnel : benchmarks rigoureux, jeux de tests métier et comparaison systématique des modèles. On ne cherche plus le « meilleur modèle du marché », mais le modèle optimal pour une micro-tâche donnée, sous contraintes de coût et de latence. Cette rigueur analytique permet d'éviter les produits « saupoudrés d'IA » dont la robustesse s'effondre face aux cas réels les plus complexes.
Vers une discipline de fer
L'IA en entreprise rejoint aujourd'hui la trajectoire de l'informatique mature : celle de l'efficacité et de la spécialisation. Certes, une nuance émerge : les LLM géants continuent de progresser en fenêtre de contexte, produisant parfois des résultats experts surprenants. Cependant, cette trajectoire reste financièrement et environnementalement coûteuse.
La spécialisation n'est plus une option technique, c'est un impératif de souveraineté. La question qui se pose désormais aux dirigeants est simple : préférez-vous rester dépendants de modèles « boîtes noires » loués à prix d'or, ou choisir la maîtrise de vos propres approches spécialisées, garantissant ainsi votre autonomie technologique et votre rentabilité à long terme ?
Source : Panorama 2026 de l'IA en entreprise élaborée par eleven strategy, La French Tech Grand Paris et VivaTech.
