En 2026, ce paradigme est révolu. Nous ne "naviguons" plus dans des outils et nous ne remplissons plus de champs de saisie. L’IA s'est transformée en une couche d'interface invisible. Désormais, l'utilisateur exprime une intention — par la voix, le geste ou l'image — et la machine orchestre la réponse. Nous quittons l'ère du "prompt" pour entrer dans celle du dialogue contextuel.
Le « Multimodal par défaut » : Un impératif d'inclusion
L’IA de 2026 ne se contente plus de lire ; elle écoute, voit, segmente et agit au cœur des flux de travail. Ce passage au multimodal par défaut n'est pas qu'une simple amélioration ergonomique, c'est un acte d'inclusion technologique.
Pendant que les cadres de bureau jonglaient avec des prompts complexes, une immense partie de la force de travail — techniciens de maintenance, opérateurs en usine, vendeurs en boutique — restait sur la touche, les mains occupées par leurs outils.
En abaissant la barrière d'usage, l'IA devient un partenaire de terrain. Parler est l'acte de communication le plus naturel : pour une population moins "digital native" ou pour un technicien en plein milieu d'une intervention critique, exprimer un besoin à haute voix est une libération. L'IA sort enfin de l'écran pour s'intégrer au geste métier.
« L’interaction avec l’IA par la voix pourrait être un bon moyen d’offrir des solutions adaptées à l’utilisation sur le terrain, dans des environnements techniques. » — Vincent Lefieux (RTE)
La révolution de la voix : Le triomphe du « Full-Duplex »
Si la voix paraissait intrusive ou gadget en 2025, elle est devenue le canal privilégié en 2026. Ce basculement repose sur une rupture technologique majeure : le passage d'une cascade de modèles (voix-texte-IA-texte-voix) à une ingénierie dédiée au temps réel.
L'écosystème français, avec des initiatives comme Moshi de Kyutai, a imposé le standard du « full-duplex ». Cette capacité de la machine à écouter et parler simultanément, avec une latence quasi nulle, change tout.
Dans les centres d’appel, cette fluidité transforme radicalement la relation client : l'IA ne se contente plus de transcrire, elle assiste en temps réel, route les appels intelligemment et assure la continuité du dossier sans couture.
En 2026, la performance perçue d'une IA ne se mesure plus à son "QI" théorique, mais au rythme de la conversation. La gestion fine des tours de parole et la capacité à être interrompue sans perdre le fil sont devenues les véritables critères de qualité de l'UX.
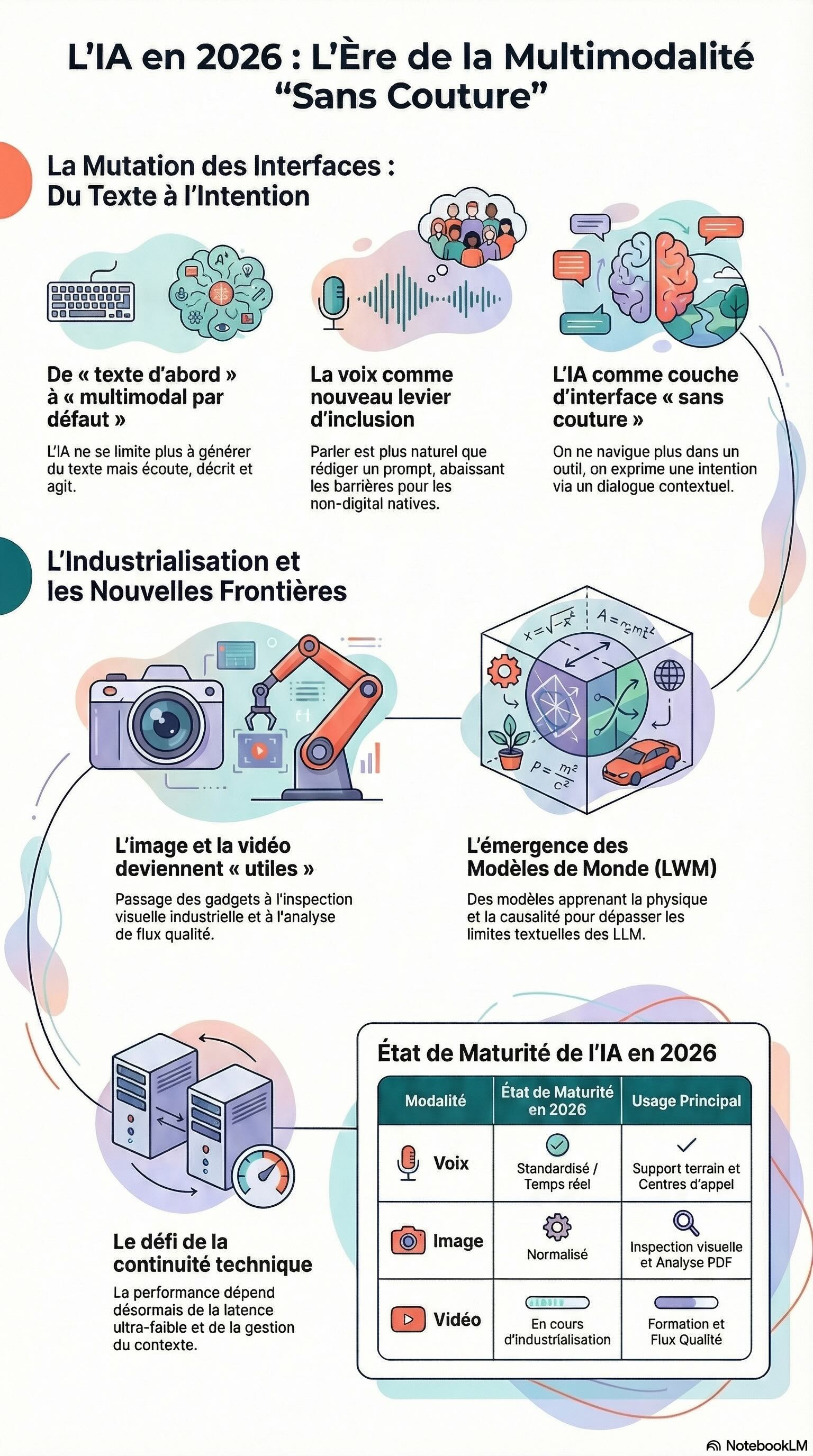
De l’image à la vidéo : Vers une industrialisation du regard
L'usage des images est désormais une commodité : extraction de données de PDF, scans, inspection visuelle de conformité. La nouvelle frontière est celle de la vidéo, bien que son industrialisation reste le grand défi de l'année.
Les entreprises cherchent à capitaliser sur les flux vidéo (formations, interventions terrain, contrôles qualité), mais se heurtent à la complexité du RAG vidéo. Indexer correctement des heures de flux pour permettre à un utilisateur de retrouver et citer précisément un instant T à l'échelle industrielle est un chantier colossal.
Pour contourner ces obstacles de coût et de latence, la tendance n'est plus au modèle unique et massif, mais à un flux cohérent de modèles spécialisés. On assemble ainsi des briques de vision, de segmentation et de transcription pour créer une intelligence visuelle performante et économiquement viable.
L'émergence des « Modèles de Monde » (LWM)
2026 marque le dépassement des limites intrinsèques des LLM. Si les modèles de langage excellent dans la prédiction statistique de mots, ils échouent souvent à comprendre la physique et la causalité. C'est ici qu'entrent en scène les Large World Models (LWM).
Ces modèles apprennent à partir de vidéos et de perceptions réelles pour comprendre les dynamiques du monde physique. Ce mouvement, amorcé par Fei-Fei Li aux États-Unis, a trouvé un écho majeur en France avec le lancement de l'initiative de Yann LeCun fin 2025. Google DeepMind, avec sa lignée Genie, participe également à cette course.
Pour l'entreprise, l'enjeu est concret : ces modèles permettent de développer des assistants capables de comprendre des scènes complexes et des séquences de gestes, ouvrant la voie à une robotique plus agile et à des simulations d'une précision inédite.
L'ère de l'agentique « sans couture »
Le passage à cette IA multimodale et physique nous confronte à trois défis persistants :
La latence : Le moindre délai brise l'illusion du dialogue naturel.
La gestion du contexte : L'IA doit maintenir le fil entre ce qui a été dit, montré et fait.
La cohérence de sortie : La capacité de la machine à expliciter et justifier son analyse visuelle.
C’est dans la résolution de ces défis que la multimodalité rencontre l’IA agentique. En 2026, comprendre ne suffit plus : l'IA doit orchestrer des opérations complexes — déclencher un workflow, ouvrir un fichier technique, produire un rapport d'incident — à partir d'une simple intention exprimée.
Nous vivons la fin de l'adaptation de l'humain à la machine. Dans ce monde où l'IA comprend nos gestes et notre environnement physique, le clavier devient le vestige d'une époque où nous étions encore limités par la barrière du texte. La machine parle enfin notre langue.
Source : Panorama 2026 de l'IA en entreprise élaborée par eleven strategy, La French Tech Grand Paris et VivaTech.
