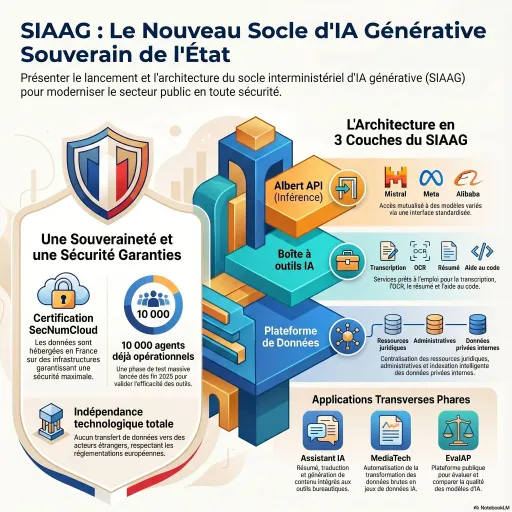
Le salon IA Paris 2026 s’impose comme un rendez-vous stratégique pour les dirigeants : agents intelligents industrialisés, souveraineté numérique, ROI, gouvernance des données et retours d’expérience concrets de grands comptes.

par Maxence Pierre-Grisel


-teaser.webp)


























-thumb.webp)






