-full.webp)
1. Le mirage de la démo parfaite
On connaît tous le refrain de la démo « wow ». L’agent se connecte à ses outils, enchaîne les réflexions avec une fluidité insolente et pond un résultat parfait sous les applaudissements de la direction. Le CODIR est conquis, le budget est débloqué. Mais dès que vous passez le cap du déploiement réel, c’est la douche froide.
La vérité ? Le manuel standard du test logiciel — tests unitaires, intégration, régression de bout en bout — est quasiment inutile face à l'imprévisibilité d'un agent. En production, le chemin d’exécution change à chaque appel et les modes de défaillance deviennent invisibles sans une instrumentation de pointe. Si vous abordez les agents avec une mentalité de développeur traditionnel, vous foncez dans le mur. Voici les leçons tirées des tranchées pour ceux qui veulent construire des systèmes, pas seulement des prototypes.
2. Leçon n°1 : Le déterminisme est un spectre, pas un binaire
Le premier réflexe d'un ingénieur face à l'instabilité est de vouloir tout verrouiller : température à zéro, cache agressif, version de modèle figée. C’est une perte de temps monumentale. Même à température zéro, le non-déterminisme est inscrit dans les lois de la physique de votre infrastructure.
Entre les stratégies de batching variable des fournisseurs d’API, l’ordre non-associatif des calculs en virgule flottante sur les cœurs GPU et les approximations de la quantification, deux appels identiques peuvent produire des vecteurs de probabilité différents. Arrêtez de courir après une perfection textuelle impossible et commencez à tester des « marges acceptables ».
L'approche pragmatique consiste à valider la structure et l'intention via des fonctions d'évaluation (LLM-as-a-judge ou analyse de code) plutôt que de comparer des caractères.
3. Leçon n°2 : Les bugs les plus vicieux se cachent entre les étapes
Contrairement aux bugs classiques qui sont locaux, les défaillances des agents sont compositionnelles. Chaque étape peut sembler techniquement correcte, mais la trajectoire globale dévie vers l'absurde. C'est ici que la déconnexion entre « succès technique » et « exactitude métier » devient totale.
Prenons un pipeline d’analyse de données : l'agent identifie la bonne table, extrait les valeurs nulles, et voit que le pipeline affiche un statut « Succès ». Il conclut alors que tout va bien. Sauf qu’il n'a pas vérifié que le pipeline a traité zéro ligne à cause d'une partition source vide. Techniquement, chaque outil a répondu « OK », mais le raisonnement a échoué.
« La question n'est pas "l'agent a-t-il appelé le bon outil ?", mais "la trajectoire de l'agent a-t-elle convergé vers le bon diagnostic ?" »
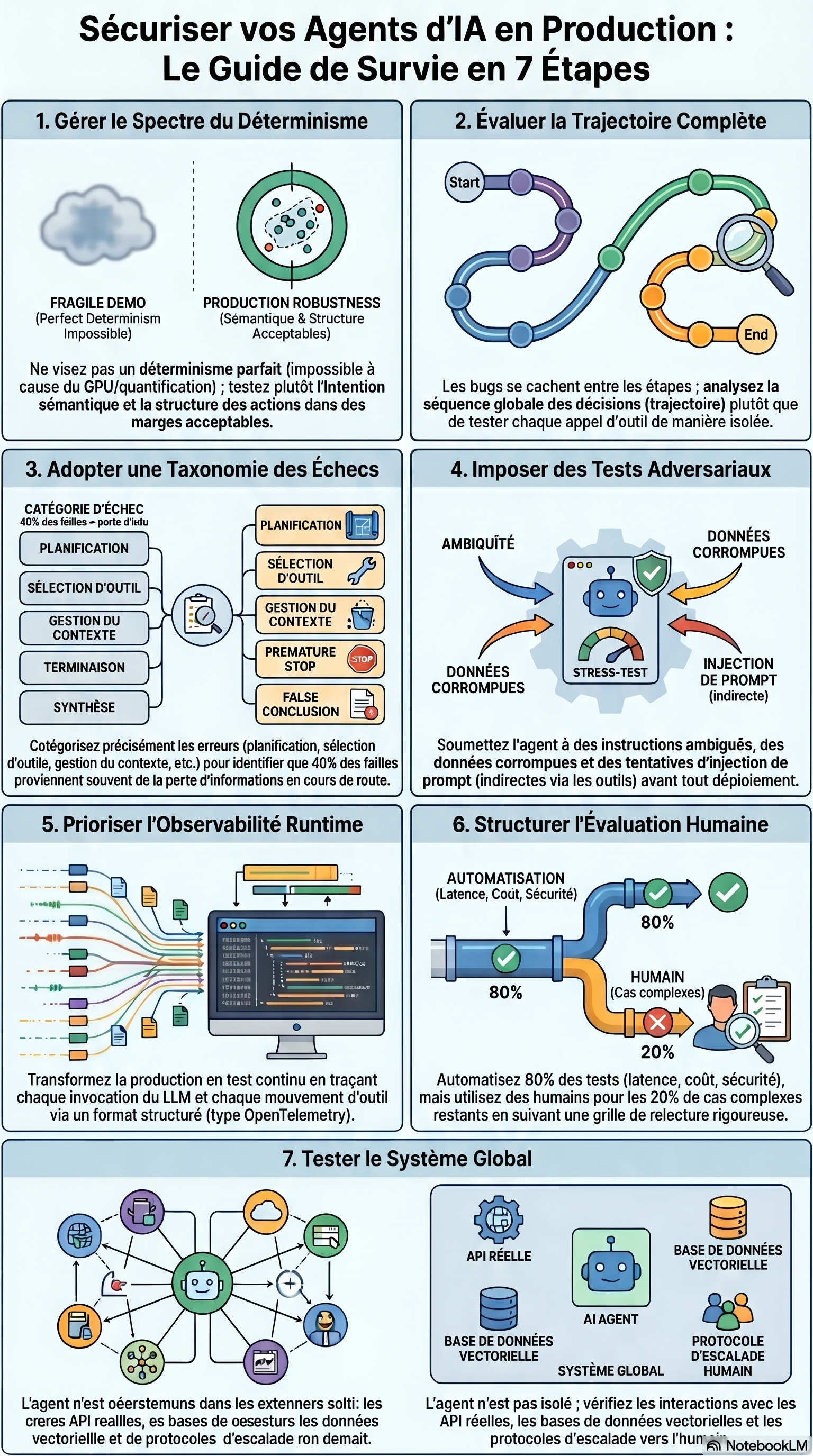
4. Leçon n°3 : Sans taxonomie des échecs, vous naviguez à vue
Dire qu’un agent « ne marche pas » ne sert à rien. Pour progresser, vous devez catégoriser chaque crash avec la précision d'un médecin légiste. Sans une taxonomie claire, vous ne saurez jamais si vous devez modifier votre code, vos prompts ou vos données.
Voici les 6 catégories de défaillances à surveiller :
Planification : La stratégie initiale est mauvaise ou la décomposition de la tâche est illogique.
Sélection d'outil : L'agent choisit le marteau pour visser.
Extraction de paramètres : Le bon outil est choisi, mais l'agent lui envoie des arguments malformés.
Gestion du contexte : L'agent oublie une information cruciale récupérée deux étapes plus tôt.
Terminaison : L'agent s'arrête trop tôt ou boucle à l'infini (le fameux "looping").
Synthèse : Les données sont bonnes, mais la réponse finale est une hallucination ou une erreur de logique.
En production, l'expérience montre que 40 % des échecs proviennent de la gestion du contexte. Si vous ne mesurez pas cela, vous passerez des semaines à optimiser vos outils alors que le problème réside dans l'architecture de vos prompts.
5. Leçon n°4 : Le test adversarial n'est pas une option, c'est une survie
Un agent en liberté rencontrera des entrées que vous n’auriez jamais osé imaginer. Votre suite de tests doit être agressive et couvrir quatre fronts :
L'ambiguïté : Donnez-lui des ordres contradictoires. Le bon comportement est de demander une clarification, pas de deviner.
La robustesse : Injectez des données bruitées ou des JSON malformés via vos API. L’agent doit se dégrader gracieusement.
Les cas limites : Poussez-le à ses limites théoriques. Il doit savoir dire « Je ne sais pas faire ça ».
L'injection de prompt indirecte : C'est le danger critique. Un acteur malveillant peut cacher des instructions de détournement à l'intérieur d'un document ou d'une réponse d'API tierce.
Pro tip : La pratique standard consiste à inclure des tentatives d'injection de prompt directement dans vos données de mock (sorties d'outils, records de base de données). Si une simple chaîne de caractères dans un résultat d'API suffit à faire dérailler votre agent, vous n'êtes pas prêt pour la production.
6. Leçon n°5 : L'observabilité est votre meilleur filet de sécurité
Le test le plus précieux est celui que vous réalisez en continu sur le trafic réel. L'observabilité transforme votre production en un laboratoire permanent.
En intégrant du tracing structuré (via OpenTelemetry), vous pouvez capturer chaque trace de raisonnement et chaque token dépensé. Cela permet de détecter des schémas de défaillance statistiquement rares — ceux qui n’apparaissent qu'une fois sur mille — mais qui flinguent votre rétention utilisateur. Un pipeline d'évaluation asynchrone qui « rejoue » et score les traces de production est l'investissement le plus rentable que vous puissiez faire.
7. Leçon n°6 : L'humain ne passe pas à l'échelle, mais il reste le juge ultime
L'automatisation a un plafond. Pour les cas complexes ou à fort enjeu, vous avez besoin de cerveaux humains. La stratégie gagnante est le 80/20 : 80 % de tests automatiques pour la non-régression, 20 % d'évaluation humaine pour la subtilité.
Cependant, l'évaluation humaine ne doit pas se faire « au doigt mouillé ». Elle nécessite des grilles de critères rigoureuses et, surtout, la mesure de l'accord inter-évaluateurs (inter-rater agreement). Si deux experts ne sont pas d'accord sur la qualité d'une réponse, votre test n'a aucune valeur scientifique. Calibrez vos évaluateurs pour que leur jugement devienne une donnée fiable qui nourrira, à terme, vos modèles d'évaluation automatisés.
8. Leçon n°7 : Testez le système entier, pas seulement le « cerveau »
L'agent n'est qu'un rouage dans une machine plus vaste. Vous pouvez avoir le meilleur modèle du monde, si l'infrastructure flanche, l'agent échoue. Les pannes les plus dévastatrices ne sont pas des hallucinations du LLM, mais des défaillances systémiques :
Une API dont le format change silencieusement.
Un index vectoriel (RAG) devenu obsolète à cause d'une tâche de rafraîchissement échouée (un cron job qui a sauté).
Un canal d'escalade vers un opérateur humain mal configuré qui tourne à vide.
Maintenez une suite de tests d'intégration système sollicitant l'infrastructure réelle. Tester l'intelligence de l'agent sur des données simulées est une chose ; vérifier qu'il peut encore accéder à ses documents un lundi matin à 9h en est une autre.
9. De la vérification à la gestion de l'incertitude
La vérité qui dérange est que le test d'agents autonomes est un chantier sans fin. Dans ce nouveau monde de l'informatique probabiliste, la couverture de test à 100 % est un fantasme de l'ancien monde.
Le succès ne repose plus sur la certitude que le système ne fera jamais d'erreur, mais sur votre capacité à détecter, catégoriser et corriger ces erreurs plus vite que vos concurrents. Nous changeons de paradigme : « Le test doit évoluer de la vérification de la correction vers la gestion de l'incertitude. » Si vous n'êtes pas prêt à gérer cette ambiguïté, restez sur des scripts déterministes. Pour les autres, la production est votre meilleur terrain d'apprentissage.
source : Journal du net
-thumb.webp)